资讯 /

剪辑:桃子 好困shibo体育游戏app平台
【新智元导读】最近,李飞飞团队仅用26分钟在Qwen基础上训出极端o1的模子,而DeepSeek更是平直选拔了阿里通义千问Qwen蒸馏开源4款模子。一个不争的事实浮出水面:夙昔称霸开源界Llama已悄然退位,新王加冕。
斯坦福李飞飞团队的一篇论文,近来在AI圈子掀翻了一场飓风。
他们仅用1000个样本,在16块H100上监督微调26分钟,训出的新模子s1-32B,竟赢得了和OpenAI o1、DeepSeek R1等顶端推理模子绝顶的数学和编码材干!
团队也再次解说了测试时Scaling的威力。
就连AI大神Karpathy齐为之感触。
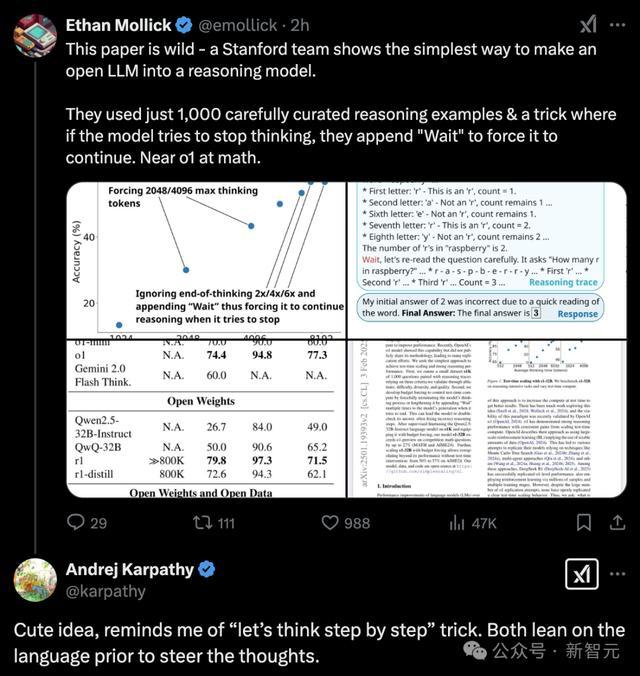
值得一提的是,说合东谈主员是基于阿里通义千问Qwen2.5-32B-Instruct,完成了推理模子的微调。
致使,在竞赛数知识题上,新模子竟将o1-preview甩在死后,朝上27%。
这一爆炸性冲突,让全天下眼神齐聚焦在了,这个来自阿里云的大模子——通义千问Qwen。
早在此之前,红遍全网的DeepSeek便选拔的亦然Qwen模子。
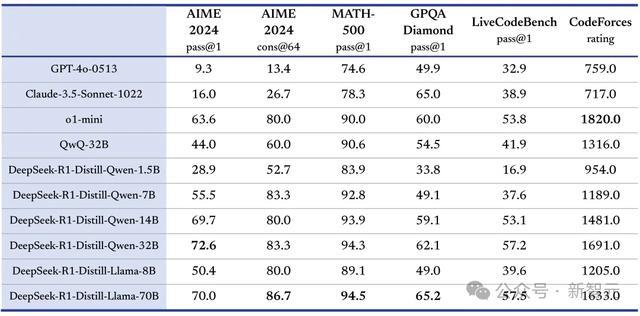
他们将DeepSeek-R1推理材干蒸馏6个模子开源给社区,其中4个齐是基于Qwen打造。基于Qwen-32B蒸馏的模子,在多项材干上性能直追o1-mini。
再一次,通义千问Qwen模子又在开源社区火了。
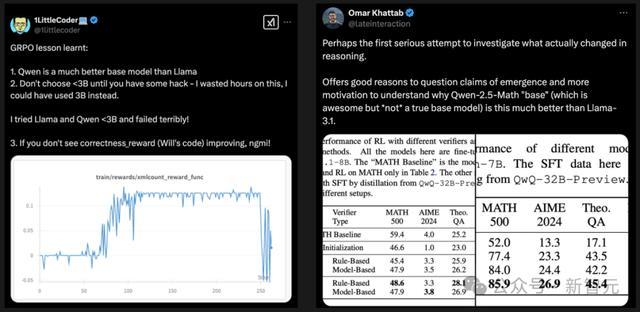
有人人冷漠:也许,这是咱们第一次崇拜尝试说合,推理中究竟发生了什么变化。
当今,咱们有充分的原理去质疑「自满」的说法,也有了更多能源去清醒,为什么Qwen-2.5-Math的基础模子要比Llama 3.1好这样多。
确凿,如今在业内,这一征象越来越成为寰球公认的事实——
凭借强盛的性能,各样化开源尺寸,以及全球最大的繁衍模子群,Qwen照旧取代Llama成为开源AI社区最流毒的标杆基座模子。
站在巨东谈主的肩膀上
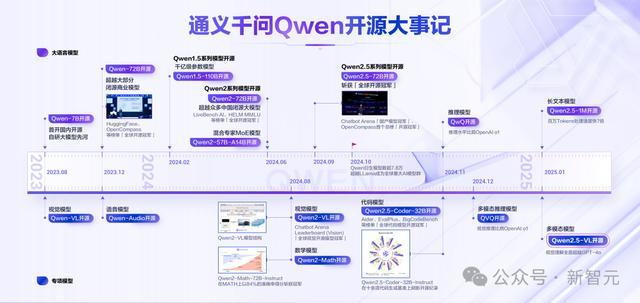
自2023年8月以来,阿里云通义千问掀翻了一场开源立异。
Qwen、Qwen1.5、Qwen2、Qwen2.5四代模子接踵开源,粉饰了大讲话模子、多模态模子、数学模子和代码模子等数十款。
在HuggingFace的Open LLM Leaderboard、Chatbot Arena大模子盲测榜单、司南OpenCompass等多个国表里巨擘榜单中,Qwen性能全球朝上,多次斩获「全球开源冠军」。
致使,有业内人人指出——
现时AI边界的诸多冲突性证据,不论是微调、蒸馏,照旧其他低老本创新技能,并非从0运行磨练,而是诞生在Qwen等基础模子的优异性能之上。
Databricks说合科学家Omar Khattab称,「更多对于Qwen的发现。我越来越征服这些论文似乎发现了一些对于Qwen模子的特质,而不一定触及推理材干的冲突」。
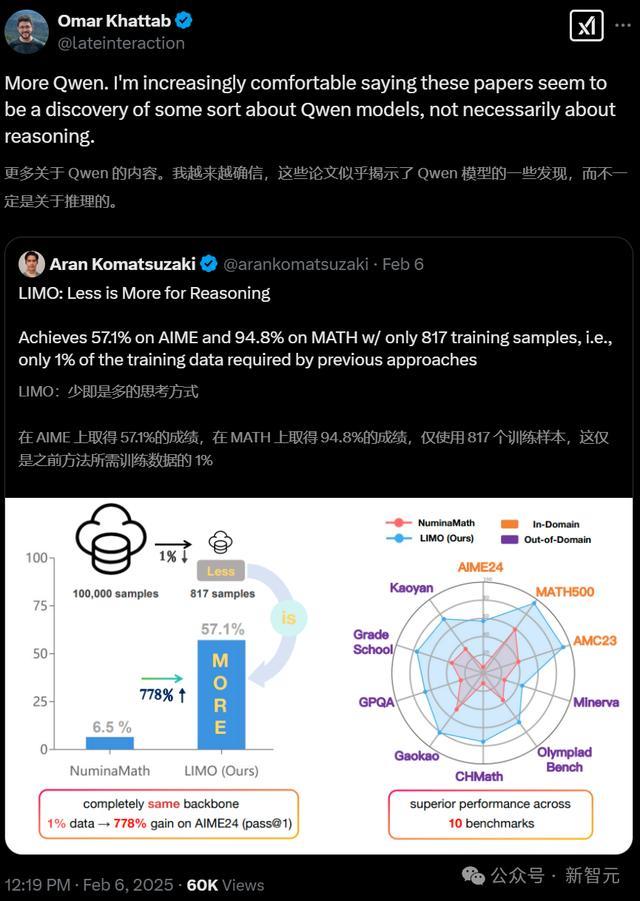
另一位来自滑铁卢大学筹算机系助理训诫Wenhu Chen对此不雅点默示极地面招供。
他默示,这基本和s1的发现一样,用约莫1000个样本就能得到访佛的磨练甩掉。
在别的模子上用雷同的数据磨练,但却足够没奏效,这是为何?
彰着,Qwen模子自己势必有一些神奇之处。

越来越多的东谈主殊途同归地发现,「咱们确实什么齐没作念,Qwen 2.5却确实什么齐能作念了。」
这就讲明,它的基础模子一定性能超强,在基准测试中相配朝上。
因为,这照旧足够不行用磨练数据质料来讲明了。

李飞飞团队s1模子用实行解说,在特定条目下,低老本(不到50好意思金)磨练如实不详产生令东谈主惊喜的甩掉。
这在很猛流程上,要归功于它所依赖的基座模子——通义千问Qwen。
若是莫得这样雄壮的模子算作支捏,思要去达成雷同的后果,惟恐并非易事。
包括DeepSeek开源蒸馏后四款Qwen模子,亦然如斯。
这也让Qwen成为鼓舞前沿技能发展的又一流毒案例。
全尺寸、全模态、多场景
不错说,阿里云Qwen模子是业界开端达成「全尺寸、全模态、多场景」的开源。
不论是1.5B、72B照旧110B,Qwen开源的模子尺寸和版块的粉饰面齐最广,让路发者和企业有了更多选拔的余步。
从2024年运行,Qwen就照旧在斥地者中领有越来越高的影响力。
比如,在全球最著名的开源社区HuggingFace数据统计中,2024年,仅Qwen2.5-1.5B-Instruct这款模子,就占到了全球模子下载量的26.6%,远高于第二名Llama-3.1-8B-Instruct-GGUF的6.44%。
而只是是视觉清醒Qwen-VL及Qwen2-VL两款模子,全球的下载量就冲突了3200万次。
就在一周前,Qwen2.5-VL全新升级,又激发了新一轮的开源社区狂热。
如今,细数海表里开源社区,Qwen的繁衍模子数目已冲突9万,平直极端了Llama系列繁衍模子。
DeepSeek和李飞飞的选拔,更是解说了Qwen系列的雄壮后劲。
在改日shibo体育游戏app平台,它必将链接创造新的古迹。